LongLong's Blog
分享IT技术,分享生活感悟,热爱摄影,热爱航天。
使用Open Dynamics Engine实现刚体动力学仿真
刚体动力学一般力学的一个分支,研究刚体在外力作用下的运动规律。它是计算机器部件的运动,舰船、飞机、火箭等航行器的运动以及天体姿态运动的力学基础。
常见的多刚体动力学商业软件有RecurDyn,ADAMS等。而ODE (Open Dynamic Engine) 是一个免费的具有工业品质的刚体动力学的库,一款优秀的开源物理引擎,它为主程序员Russell Smith和几位开源社区贡献者共同努力下开发的。它能很好地仿真现实环境中的可移动物体,它是快速,强健和 可移植的。而且它有内建的碰撞检测系统。
1. ODE的安装
ODE的安装非常简单,从其官方网站https://www.ode.org,找到在BitBucket中的代码库地址,使用git直接下载整个代码库,并使用cmake进行编译安装。此外也可以使用各Linux发行版的包管理器进行安装。
pacman -S ode #下载源代码 git clone https://bitbucket.org/odedevs/ode.git cmake . make其中还附带了Python的API,在源代码的bindings/python目录下,运行其中的setup.py脚本可以完成Python接口的编译和安装。
python setup.py build python setup.py install
2. ODE的模块组成
ODE中对于整个模型分为世界World,刚体Body,约束(铰接)Joints ,力Force,几何体Geometry等。通过在World中增加Boby及Joints等连接约束关系,建立整个多刚体等力学模型,并通过不断循环时间步长通过积分来计算整个系统的下个状态。代码的基本框架如下
import ode; #创建时间 world = ode.World(); #设置重力 world.setGravity((0, -9.8, 0)); #新建一个刚体 b1 = ode.Body(world); #设置时间补偿 TIME_STEP = 0.01; #进行1000次积分循环 for i in range(0, 1000): #得到当前刚体的位置 x1, y1, z1 = b1.getPosition(); world.step(TIME_STEP);
3. 双摆的运动模拟及双摆曲线的绘制
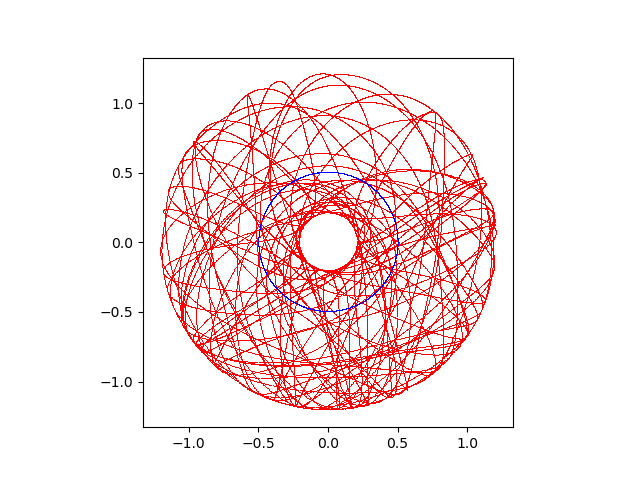
建立一个双摆的模型并绘制两个摆动点的轨迹,两个质点的初始位置和初始速度分别为,(0, -0.5, 0),(10, 0, 0)和(0.5, -1.0, 0),(0, 0, 0)。并建立连接,由于这里是二维问题,使用球铰和圆柱铰并没有本质区别,就直接使用球铰了,其他类型的铰还需要给定方向等相关的参数。程序的代码如下
import numpy; import ode; from matplotlib import pyplot as plt; import matplotlib.animation as animation; if __name__ == '__main__': #创建世界 world = ode.World(); world.setGravity((0, -9.8, 0)); #创建第一个质点 b1 = ode.Body(world); #设置初始位置和速度 b1.setPosition((0, -0.5, 0)) b1.setLinearVel((10, 0, 0)); #设置质量和外形 m1 = ode.Mass(); m1.setSphereTotal(0.1, 0.05); b1.setMass(m1); #创建第二个质点 b2 = ode.Body(world); #设置初始位置,默认初始速度为0 b2.setPosition((0.5, -1.0, 0)); #设置质量和外形 m2 = ode.Mass(); m2.setSphereTotal(0.1, 0.05); b2.setMass(m2); #创建第一个质点和环境的约束 j1 = ode.BallJoint(world); j1.attach(b1, ode.environment); j1.setAnchor((0.0, 0.0, 0.0)); #创建第二个质点和第一个质点之间的约束 j2 = ode.BallJoint(world); j2.attach(b1, b2); j2.setAnchor((0, -0.5, 0)); #设置时间步长 TIME_STEP = 0.01; fig, ax = plt.subplots(); for i in range(0, 20000): #分别获得两个质点的位置 x1, y1, z1 = b1.getPosition(); x2, y2, z2 = b2.getPosition(); #绘制当前的位置 plt.plot(x1, y1, 'b,'); plt.plot(x2, y2, 'r,'); #进入下一时刻 world.step(TIME_STEP); #设置绘图的X和Y轴保持相同的比例 ax.set_aspect('equal'); #保持绘制的图片 plt.savefig('1.png');由于Python接口只能支持Python2,如今已经几乎不能用了,附上C版本的代码
#include <ode/ode.h> int main() { const dReal TIME_STEP = 0.01; const dReal TIME_STOP = TIME_STEP * 200; dInitODE(); dWorldID w = dWorldCreate(); dWorldSetGravity(w, 0.0, -9.8, 0.0); dBodyID b1 = dBodyCreate(w); dBodySetPosition(b1, 0.0, -0.5, 0.0); dBodySetLinearVel(b1, 10.0, 0.0, 0.0); dMass m1; dMassSetSphereTotal(&m1, 0.1, 0.05); dBodySetMass(b1, &m1); dBodyID b2 = dBodyCreate(w); dBodySetPosition(b2, 0.5, -1.0, 0.0); dMass m2; dMassSetSphereTotal(&m2, 0.1, 0.05); dBodySetMass(b2, &m2); dJointGroupID jd = dJointGroupCreate(10); dJointID j1 = dJointCreateBall(w, jd); dJointAttach(j1, b1, 0); dJointSetBallAnchor(j1, 0.0, 0.0, 0.0); dJointID j2 = dJointCreateBall(w, jd); dJointAttach(j2, b1, b2); dJointSetBallAnchor(j2, 0.0, -0.5, 0.0); dReal total_time = 0.0; while (total_time < TIME_STOP) { const dReal* u1 = dBodyGetPosition(b1); const dReal* u2 = dBodyGetPosition(b2); printf("%f\t%f\t%f\t%f\n", u1[0], u1[1], u2[0], u2[1]); dWorldStep(w, TIME_STEP); total_time += TIME_STEP; } dBodyDestroy(b1); dBodyDestroy(b2); dJointDestroy(j1); dJointDestroy(j2); dJointGroupDestroy(jd); dWorldDestroy(w); dCloseODE(); return 0; }运行后得到的双摆轨迹曲线如下图所示,混乱中似乎有带有一些美感。
使用循环神经网络预测股价
神经网络可以类似最小二乘法一样作为一种基于经验的数据拟合方法,相比最小二乘法神经网络在拟合数据时不需要对输出输出之间的函数关系有提前的认识,而是通过引入大量的参数试图通过对参数的优化得到最佳的拟合结果。而实际中可通过对时间序列的拟合,实现对时间序列的未来趋势进行预测,如气温、客流、股价等。而循环神经网络(RNN)作为一种针对时间序列的方法,充分利用时间序列中前后数据的关联性,实现更高的拟合效果。
这里以股价的预测为例,使用Tensorflow中的keras实现循环神经网络的建模、训练实现对上证综合指数的预测。
1. 获得训练数据
为实现训练,首先需要获得用于训练的数据集,这里通过Tushare获得上证综合指数的历史数据,其还提供了其他各种财经数据,专业版需要注册获得接口TOKEN使用,普通版本可以直接获取数据不需要注册,目前暂时还可以使用。其返回的数据为pandas封装,需要安装Python的pandas模块,可以使用pip直接安装,同时安装Tensorflow,如果使用的CUDA为10.1版本,对应的cuDNN需要选择7.4.x,Tensorflow则可选择安装2.3.0版本。
pip install pandas pip install tensorflow==2.3.0Tushare的使用非常简单,直接调用获取数据的方法即可返回数据集,需要传入的参数包括股票的代码,上证综合指数为sh000001,以及获取数据的日期区间。同时将数据按照时间索引进行排序,获取数据的代码如下
data = tushare.get_hist_data('sh000001', '2011-01-01', '2020-12-31'); data.index = data.index.astype('datetime64[ns]'); data = data.sort_index()['close'].values.reshape(-1, 1);2. 生成训练数据集
训练数据集一般包括两个数组x_train和y_train,其中x_train数组中的一个元素为一个数据输入,y_train数组中的一个元素为一个数据输出,输入和输出数据都可以含有多个数据。例如在使用循环神经网络时输入的数据就是预测时刻之前的n个时刻的数据,同时在生成训练集前,对数据进行归一化处理
#归一化处理 scl = MinMaxScaler(); data = scl.fit_transform(data); #预测使用的数据点个数及预测的数据点个数 look_back = 30; forward_days = 1; #生成训练数据集 x_train, y_train = [], []; for i in range(0, len(data) - look_back - forward_days + 1): x_train.append(data[i : (i + look_back)]); y_train.append(data[(i + look_back) : (i + look_back + forward_days)]); x_train = numpy.array(x_train); y_train = numpy.array(y_train);
3. 构造循环神经网络模型
数据准备完成后便是构造循环神经网络模型,这里使用tensorflow中提供的keras来定义一个循环神经网络,包括两个长短期记忆层和1个全连接层,其代码如下
#初始化循环神经网络模型 model = Sequential(); #第一层长短期记忆层 model.add(LSTM(100, input_shape=(look_back, 1), return_sequences=True)); #防止过拟合增加Dropout层 model.add(Dropout(0.2)); #第二层长短期记忆层 model.add(LSTM(80)); #最后的全连接层 model.add(Dense(forward_days, activation='tanh')); #编译模型 model.compile(loss='mean_squared_error', optimizer='adam'); #进行数据拟合 model.fit(x_train, y_train, epochs=100, batch_size=16); #保存训练得到的模型 model.save(model_file);在使用Ryzen 3600+RTX2080Super的环境下,仅使用CPU训练大约耗时52s,使用CUDA加速后则只需要18s。为了对比运行速度,在训练过程中可通过配置以下环境变量实现禁用CUDA加速。
import os; os.environ['CUDA_VISIBLE_DEVICES'] = '-1';
4. 进行预测
在完成训练得到模型后,就可以使用模型对未来的数据进行预测了,预测时需要构造与训练时格式相同的x_test数组,通过模型可以得到对应的y_test预测结果,其代码如下
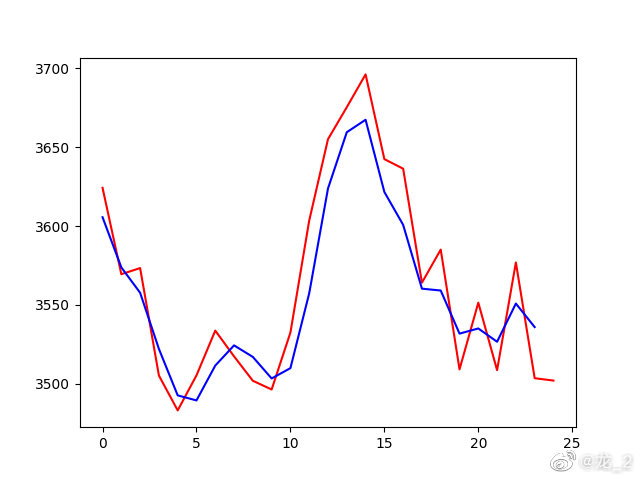
#获取预测需要的数据,并对数据进行处理 data = tushare.get_hist_data(no, '2021-01-01'); data.index = data.index.astype('datetime64[ns]'); data = data.sort_index()['close'].values.reshape(-1, 1); data = scl.fit_transform(data); #构造预测的输入数据集 x_test = []; for i in range(0, len(data) - look_back - forward_days + 1): x_test.append(data[i : (i + look_back)]); x_test = numpy.array(x_test); #使用模型对结果进行预测 y_test = model.predict(x_test);同时使用matplotlib还可以绘制预测的结果和实际的结果的对比曲线
import matplotlib.pyplot as plt; plt.plot(scl.inverse_transform(y_test.reshape(-1, 1))[0:-1]); plt.plot(scl.inverse_transform(data[look_back + 1:])); plt.show();
5.结果
红线是实际的曲线,蓝线是预测的曲线,总体上匹配度还可以。