使用循环神经网络预测股价
神经网络可以类似最小二乘法一样作为一种基于经验的数据拟合方法,相比最小二乘法神经网络在拟合数据时不需要对输出输出之间的函数关系有提前的认识,而是通过引入大量的参数试图通过对参数的优化得到最佳的拟合结果。而实际中可通过对时间序列的拟合,实现对时间序列的未来趋势进行预测,如气温、客流、股价等。而循环神经网络(RNN)作为一种针对时间序列的方法,充分利用时间序列中前后数据的关联性,实现更高的拟合效果。
这里以股价的预测为例,使用Tensorflow中的keras实现循环神经网络的建模、训练实现对上证综合指数的预测。
1. 获得训练数据
为实现训练,首先需要获得用于训练的数据集,这里通过Tushare获得上证综合指数的历史数据,其还提供了其他各种财经数据,专业版需要注册获得接口TOKEN使用,普通版本可以直接获取数据不需要注册,目前暂时还可以使用。其返回的数据为pandas封装,需要安装Python的pandas模块,可以使用pip直接安装,同时安装Tensorflow,如果使用的CUDA为10.1版本,对应的cuDNN需要选择7.4.x,Tensorflow则可选择安装2.3.0版本。
pip install pandas pip install tensorflow==2.3.0Tushare的使用非常简单,直接调用获取数据的方法即可返回数据集,需要传入的参数包括股票的代码,上证综合指数为sh000001,以及获取数据的日期区间。同时将数据按照时间索引进行排序,获取数据的代码如下
data = tushare.get_hist_data('sh000001', '2011-01-01', '2020-12-31'); data.index = data.index.astype('datetime64[ns]'); data = data.sort_index()['close'].values.reshape(-1, 1);2. 生成训练数据集
训练数据集一般包括两个数组x_train和y_train,其中x_train数组中的一个元素为一个数据输入,y_train数组中的一个元素为一个数据输出,输入和输出数据都可以含有多个数据。例如在使用循环神经网络时输入的数据就是预测时刻之前的n个时刻的数据,同时在生成训练集前,对数据进行归一化处理
#归一化处理 scl = MinMaxScaler(); data = scl.fit_transform(data); #预测使用的数据点个数及预测的数据点个数 look_back = 30; forward_days = 1; #生成训练数据集 x_train, y_train = [], []; for i in range(0, len(data) - look_back - forward_days + 1): x_train.append(data[i : (i + look_back)]); y_train.append(data[(i + look_back) : (i + look_back + forward_days)]); x_train = numpy.array(x_train); y_train = numpy.array(y_train);
3. 构造循环神经网络模型
数据准备完成后便是构造循环神经网络模型,这里使用tensorflow中提供的keras来定义一个循环神经网络,包括两个长短期记忆层和1个全连接层,其代码如下
#初始化循环神经网络模型 model = Sequential(); #第一层长短期记忆层 model.add(LSTM(100, input_shape=(look_back, 1), return_sequences=True)); #防止过拟合增加Dropout层 model.add(Dropout(0.2)); #第二层长短期记忆层 model.add(LSTM(80)); #最后的全连接层 model.add(Dense(forward_days, activation='tanh')); #编译模型 model.compile(loss='mean_squared_error', optimizer='adam'); #进行数据拟合 model.fit(x_train, y_train, epochs=100, batch_size=16); #保存训练得到的模型 model.save(model_file);在使用Ryzen 3600+RTX2080Super的环境下,仅使用CPU训练大约耗时52s,使用CUDA加速后则只需要18s。为了对比运行速度,在训练过程中可通过配置以下环境变量实现禁用CUDA加速。
import os; os.environ['CUDA_VISIBLE_DEVICES'] = '-1';
4. 进行预测
在完成训练得到模型后,就可以使用模型对未来的数据进行预测了,预测时需要构造与训练时格式相同的x_test数组,通过模型可以得到对应的y_test预测结果,其代码如下
#获取预测需要的数据,并对数据进行处理 data = tushare.get_hist_data(no, '2021-01-01'); data.index = data.index.astype('datetime64[ns]'); data = data.sort_index()['close'].values.reshape(-1, 1); data = scl.fit_transform(data); #构造预测的输入数据集 x_test = []; for i in range(0, len(data) - look_back - forward_days + 1): x_test.append(data[i : (i + look_back)]); x_test = numpy.array(x_test); #使用模型对结果进行预测 y_test = model.predict(x_test);同时使用matplotlib还可以绘制预测的结果和实际的结果的对比曲线
import matplotlib.pyplot as plt; plt.plot(scl.inverse_transform(y_test.reshape(-1, 1))[0:-1]); plt.plot(scl.inverse_transform(data[look_back + 1:])); plt.show();
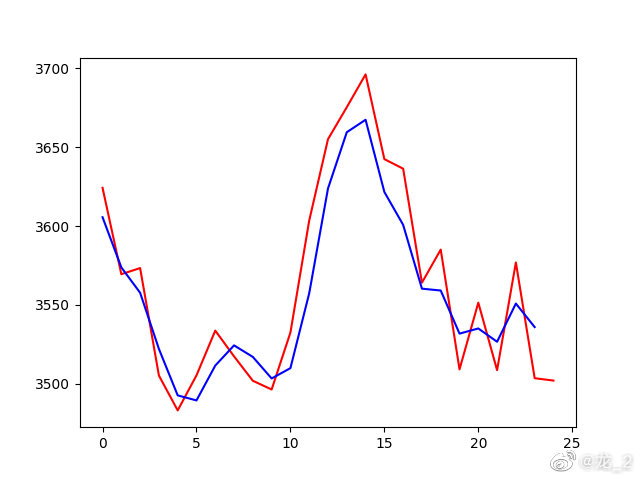
5.结果
红线是实际的曲线,蓝线是预测的曲线,总体上匹配度还可以。