LongLong's Blog
分享IT技术,分享生活感悟,热爱摄影,热爱航天。
使用OpenCL进行异构计算
目前应用比较广泛的异构计算框架是nVIDIA公司的CUDA,目前无论是开源还是商业软件的GPU加速基本都采用了CUDA,主要应用在物理仿真和机器学习等运算密集的应用场景中。然而实用CUDA的条件是具有一块nVIDIA的显卡,而在Intel核显和AMD显卡下则无法使用,就可移植性来说还是存在一些缺陷,期待以后能够有开放版本的CUDA。
OpenCL作为一个开放的异构计算框架在CUDA的流行下一直都没有能够得到广泛的应用,其原理是在运行时有OpenCL的实现层将特定语法的C语言代码(称为Kernel)编译为异构计算硬件的机器代码,通过命令队列的方式将计算任务分配给每一个异构计算单元,每一个异构计算单元执行Kernel得出运算结果。CUDA总体上也是类似的逻辑。
1. 在macOS上使用OpenCL
macOS上安装XCode后就会默认安装OpenCL,引用的头文件为
#include <OpenCL/opencl.h>如果考虑代码在其他平台的可移植性,一般可以写成
#ifdef __APPLE__ #include <OpenCL/opencl.h> #else #include <CL/cl.h> #endif编译使用了OpenCL代码的命令为
gcc -framework opencl hello.c
2. 使用OpenCL实现矩阵乘法
以下将使用OpenCL实现一个矩阵乘法的算法,其代码如下
#include <OpenCL/opencl.h> #include <stdio.h> #include <stdlib.h> #define KERNEL(...)#__VA_ARGS__ //Kernel代码,计算乘积矩阵i行j列的值 const char* KernelSource = KERNEL( __kernel void matrix_mul(int m, int p, int n, __global float* A, __global float* B, __global float* C) {\n int i = get_global_id(0);\n int j = get_global_id(1);\n float sum = 0;\n for (int k = 0; k < p; k++) {\n sum += A[i * m + k] * B[p * k + j];\n }\n C[i * m + j] = sum;\n } ); int main() { int err; cl_device_id device_id; cl_context context; cl_command_queue commands; cl_program program; cl_kernel kernel; int gpu = 1; //获取计算设备,这里获取GPU设备 err = clGetDeviceIDs(NULL, gpu ? CL_DEVICE_TYPE_GPU : CL_DEVICE_TYPE_CPU, 1, &device_id, NULL); if (err != CL_SUCCESS) { return EXIT_FAILURE; } //初始化上下文和命令队列 context = clCreateContext(0, 1, &device_id, NULL, NULL, &err); if (!context) { return EXIT_FAILURE; } commands = clCreateCommandQueue(context, device_id, 0, &err); if (!commands) { return EXIT_FAILURE; } //编译Kernel代码 program = clCreateProgramWithSource(context, 1, (const char**) & KernelSource, NULL, &err); if (!program) { return EXIT_FAILURE; } err = clBuildProgram(program, 0, NULL, NULL, NULL, NULL); if (err != CL_SUCCESS) { return EXIT_FAILURE; } kernel = clCreateKernel(program, "matrix_mul", &err); if (!kernel || err != CL_SUCCESS) { return EXIT_FAILURE; } int count = 800; int m = count; int p = count; int n = count; cl_mem input1; cl_mem input2; cl_mem output; //生成两个随机矩阵 float A[count][count]; float B[count][count]; for (int i = 0; i < count; i++) { for (int j = 0; j < count; j++) { A[i][j] = (float) rand() / RAND_MAX; B[i][j] = (float) rand() / RAND_MAX; } } //创建将输入的两个矩阵和乘积结果矩阵的入缓冲区,并将随机生成的数据写入缓冲区 input1 = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(float) * m * p, NULL, NULL); input2 = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(float) * p * n, NULL, NULL); output = clCreateBuffer(context, CL_MEM_WRITE_ONLY, sizeof(float) * m * n, NULL, NULL); if (!input1 || !input2 || !output) { return EXIT_FAILURE; } err = 0; err = clEnqueueWriteBuffer(commands, input1, CL_TRUE, 0, m * p * sizeof(float), A, 0, NULL, NULL); err |= clEnqueueWriteBuffer(commands, input2, CL_TRUE, 0, p * n * sizeof(float), B, 0, NULL, NULL); if (err != CL_SUCCESS) { return EXIT_FAILURE; } //设置Kernel参数 err = 0; err = clSetKernelArg(kernel, 0, sizeof(cl_mem), &m); err |= clSetKernelArg(kernel, 1, sizeof(cl_mem), &p); err |= clSetKernelArg(kernel, 2, sizeof(cl_mem), &n); err |= clSetKernelArg(kernel, 3, sizeof(cl_mem), &input1); err |= clSetKernelArg(kernel, 4, sizeof(cl_mem), &input2); err |= clSetKernelArg(kernel, 5, sizeof(cl_mem), &output); if (err != CL_SUCCESS) { return EXIT_FAILURE; } //设置计算任务,并开始计算 //其中global中设置的两个变量对应Kernel中get_global_id中获取的两个值 size_t local[2] = {20, 20}; size_t global[2] = {count, count}; err = clEnqueueNDRangeKernel(commands, kernel, 2, NULL, global, local, 0, NULL, NULL); if (err != CL_SUCCESS) { printf("%d\n", err); return EXIT_FAILURE; } //等待计算结果并将结果读入数组 float C[m][n]; clFinish(commands); err = clEnqueueReadBuffer(commands, output, CL_TRUE, 0, sizeof(float) * m * n, C, 0, NULL, NULL); if (err != CL_SUCCESS) { return EXIT_FAILURE; } //清理释放资源 clReleaseMemObject(input1); clReleaseMemObject(input2); clReleaseMemObject(output); clReleaseProgram(program); clReleaseKernel(kernel); clReleaseCommandQueue(commands); clReleaseContext(context); //输出结果 for (int i = 0; i < m; i++) { for (int j = 0; j < n; j++) { printf("%f\t", C[i][j]); } printf("\n"); } return 0; }
3. 性能比较
对比OpenCL版本的矩阵乘法和普通CPU版本的矩阵乘法代码,矩阵规模为800X800的方阵
#OpenCL版本 real 0m0.568s user 0m0.025s sys 0m0.022s #CPU版本 real 0m2.875s user 0m2.862s sys 0m0.009s在矩阵规模较大时OpenCL版本会明显快于CPU版本,而在矩阵规模较小时会慢于CPU版本,主要是由于OpenCL版本的初始化,编译Kernel,复制数据到缓冲区这些开销在计算规模不大时会占总计算时间的很大比例。
4. 在Python中使用OpenCL
在C/C++中使用OpenCL时很多初始化的操作会相对繁琐,如果在Python等脚本语言中使用则可以简化这些处理使得代码更加简单。Python的OpenCL库为PyOpenCL,在安装了硬件所需OpenCL的SDK后编译安装PyOpenCL即可,另外通过安装Pocl(Portable Computing Language),还可以将OpenCL代码运行在CPU环境中,可以在无可用GPU环境下开发和调试OpenCL代码。
PyOpenCL主页给出的代码示例为向量相加,其中使用到了Python中常用的数值计算库Numpy,PyOpenCL可以直接对Numpy中的向量数据进行操作
from __future__ import absolute_import, print_function import numpy as np import pyopencl as cl a_np = np.random.rand(50000).astype(np.float32) b_np = np.random.rand(50000).astype(np.float32) ctx = cl.create_some_context() queue = cl.CommandQueue(ctx) mf = cl.mem_flags a_g = cl.Buffer(ctx, mf.READ_ONLY | mf.COPY_HOST_PTR, hostbuf=a_np) b_g = cl.Buffer(ctx, mf.READ_ONLY | mf.COPY_HOST_PTR, hostbuf=b_np) prg = cl.Program(ctx, """ __kernel void sum( __global const float *a_g, __global const float *b_g, __global float *res_g) { int gid = get_global_id(0); res_g[gid] = a_g[gid] + b_g[gid]; } """).build() res_g = cl.Buffer(ctx, mf.WRITE_ONLY, a_np.nbytes) prg.sum(queue, a_np.shape, None, a_g, b_g, res_g) res_np = np.empty_like(a_np) cl.enqueue_copy(queue, res_np, res_g) # Check on CPU with Numpy: print(res_np - (a_np + b_np)) print(np.linalg.norm(res_np - (a_np + b_np)))
配置SAML单点登录环境
在和其他网站共享用户账号时,需要实现用户账号对接和单点登录的功能。而比较多的第三方账号登录功能多以OAuth的方式实现,而OAuth需要进行服务器之间的通信来认证授权并获取用户信息,会给服务器带来一些额外的开销和不确定性。而SAML则是一种完全不存在服务器直接通信的认证方式。
1. SAML 认证方式
SAML的认证方式包括客户端Client,服务提供者SP和认证提供者IdP,用户访问SP,SP会返回给用户一个302重定向,将用户重定向到对应的IdP页面,用户输入登录信息后,IdP会根据用户的来源返回给用户一个POST到之前SP的表单,SP确认信息完成登录过程。其流程图如下所示
可以看到SP和IdP之间只通过引导用户重定向来交换数据,并不直接进行通信。为了确保通信的安全,建议SP和IdP都是用HTTPS协议。
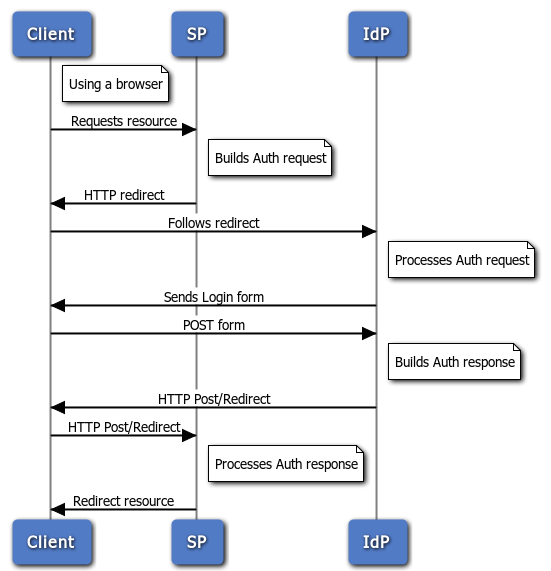
2. 配置 SimpleSAMLphp
SimpleSAMLphp是一个使用PHP实现的SAML类库,同时提供了一个可配置为SP或Idp的Web服务。其Web服务的Nginx配置如下
root /srv/http/simplesamlphp/www/; location / { index index.html index.htm index.php; } location ~ \.php { fastcgi_param PHP_VALUE "post_max_size=16M"; fastcgi_pass 127.0.0.1:9000; fastcgi_split_path_info ^(.+?\.php)(/.+)$; fastcgi_param PATH_INFO $fastcgi_path_info; fastcgi_index index.php; include fastcgi.conf; }其中主要两个问题,由于是用了path_info形式的URL风格,PHP的location不能配置成为\.php$,同时需要增加fastcgi_split_path_info的配置。
完成Web服务配置后,修改config/config.php,其中auth.adminpassword需要更改,否则一些功能会不能使用。将enable.saml20-idp设置为true。
'auth.adminpassword' => '123456', 'enable.saml20-idp' => true,另外SimpleSAMLphp是用了PHP的Session作为会话保持,在使用多台服务器做负载均衡的情况下会存在不能共享的问题,这里可以开启SimpleSAMLphp使用MySQL存储Session的功能,其会在配置的数据库中创建三个表来存储Session信息
'store.sql.dsn' => 'mysql:host=localhost;port=3306;dbname=test', 'store.sql.username' => 'root', 'store.sql.password' => '', 'store.sql.prefix' => 'SimpleSAMLphp',
3. 配置SP并增加Idp配置
SimpleSAMLphp的SP配置在config/authsources.php文件中参考其中default-sp进行配置即可,其中需要注意有些Idp要求证书的签名算法必须使用SHA256,则此时使用SHA256生成签名证书,并将signature.algorithm设置为
'signature.algorithm' => 'http://www.w3.org/2001/04/xmldsig-more#rsa-sha256',访问SimpleSAMLphp的后台工具/module.php/core/frontpage_federation.php,可以查看到配置的SP,点击Show metadata可以看到此SP对应的metadata信息的XML文本,此XML可以用于某些Idp的配置。
增加Idp时,首先获得对方Idp的metadata信息,其中主要包括SingleSignOnService和SingleLogoutService以及签名证书的一些信息。将这些信息添加到metadata/saml20-idp-remote.php文件中的$metadata数组中即可。
而对于提供了metadata的XML的Idp,则可以使用SimpleSAMLphp提供的工具将XML转换为PHP数组,工具地址为/admin/metadata-converter.php,需要输入auth.adminpassword的密码。
4. 代码中即成SAML认证
在代码中需要调用SAML认证的逻辑时,可以通过引用SimpleSAMLphp的代码来实现,注意这里必须引用提供Web服务的SimpleSAMLphp代码,因为需要使用到配置文件。
//加载autoload require_once(SAML_ROOT . 'lib/_autoload.php'); //实例化认证对象,并指定使用的SP $as = new SimpleSAML_Auth_Simple($conf['sp']); //指定使用的Idp进行认证,如果没有认证会进行SAML的跳转 $as->requireAuth(array( 'saml:idp' => $conf['idp'], )); //如果已经认证成功则获取用户信息 $user_attributes = $as->getAttributes();