LongLong's Blog
分享IT技术,分享生活感悟,热爱摄影,热爱航天。
使用Nginx动态缩放图片
在使用图片时,为了加快加载速度一般会根据页面中实际使用的尺寸使用原图的缩略图,一般情况各种规格的缩略图会在上传之后进行生成。而实际产品设计中可能会用到没有生成过的规格的缩略图,而增加一种规格的缩略图会是一个很大的维护操作,比较容易想到的方法是在实际使用时动态生成缩略图。
1. Nginx的image filter模块
Nginx原生的image filter模块使用libgd对图片进行操作,支持缩放,旋转,裁剪三种操作。例如以下配置可将图片缩放为150X100,并旋转90度
location /img/ { proxy_pass http://backend; image_filter resize 150 100; image_filter rotate 90; }配合Nginx的Lua脚本可以实现对图片的动态缩放要求,例如以下配置可提取URL中的缩放后图片宽高,进行缩放
location /resize/ { set $w 0; set $h 0; image_filter resize $w $h; rewrite_by_lua_block { --通过正则表达式提取图片缩放后的宽和高 local m = ngx.re.match(ngx.var.uri, '^/resize(.*[^/]+)_(\\d+)x(\\d+)\\.jpg$'); --匹配失败则返回404 if not m then ngx.exit(ngx.HTTP_NOT_FOUND); end --设置缩放后的宽和高 ngx.var.w = m[2]; ngx.var.h = m[3]; --执行Rewrite ngx.req.set_uri(m[1] .. '.jpg', false); } }注意image filter模块进行的缩放操作是保持宽高比的。另外由于使用的是libgd缩放的质量和性能都比较一般,同时如果需要根据图片的原始信息做更加复杂的处理,则image filter模块会较为难以实现。
2. Nginx配合OpenCV Lua模块
OpenCV作为一个比较强大的计算机视觉处理库,实现图片的缩放自然很简单,同时相比安装Lua的OpenCV模块,自己写一个wrapper反而来得更加容易一些
#include <opencv2/opencv.hpp> #include <vector> #include <cstring> #include <iostream> //这里必须声明为extern "C",否则在调用时会提示找不到方法 extern "C" { uchar* im_resize(const char* buf, int len, int h, int w, const char* ext, int& ret_len); } uchar* im_resize(const char* buf, int len, int h, int w, const char* ext, int& ret_len) { //破获抛出的异常,便于在Lua中进行调试 try { //通过图片二进制数据流获得图片矩阵 cv::Mat im = cv::imdecode(std::vector<char>(buf, buf + len), CV_LOAD_IMAGE_COLOR); //这里声明为UMat是便于在支持OpenCL的环境中进行加速 cv::UMat src; cv::UMat dst; src = im.getUMat(cv::ACCESS_RW); //调用OpenCV的缩放方法 cv::resize(src, dst, cv::Size(h, w)); //重新生成压缩格式 std::vector<uchar> ret; cv::imencode(ext, dst, ret); //返回结果 ret_len = ret.size(); return ret.data(); } catch (cv::Exception& e) { std::cout << e.what() << std::endl; return NULL; } }编译的命令为
g++ -O2 -shared -fPIC `pkg-config opencv` resize.cc -o libresize.so在nginx中使用Lua脚本进行调用,在Luajit中可以使用ffi模块直接调用动态库中的函数,需要使用ffi.cdef对函数的格式进行声明(类似include头文件)
location /resize/ { content_by_lua_block { --使用ffi直接调用动态库中的函数 local ffi = require('ffi'); --声明函数的格式,类似include头文件 ffi.cdef[[ char* im_resize(const char* buf, int len, int h, int w, const char* ext, int& ret_len); ]] ---加载动态库 local resize = ffi.load('./libresize.so'); --通过正则表达式提取图片缩放后的宽和高 local m = ngx.re.match(ngx.var.uri, '^/resize(.*[^/]+)_(\\d+)x(\\d+).jpg$'); --匹配失败则返回404 if not m then ngx.exit(ngx.HTTP_NOT_FOUND); end --获取图像内容 local res = ngx.location.capture(m[1] .. '.jpg'); --如果没有返回200则直接返回对应的状态 if res.status ~= ngx.HTTP_OK then ngx.exit(res.status); end --获得图像的内容和长度 local body = res.body; local n = string.len(body); --初始化结果长度指针 local ret_len = ffi.new('int[1]'); --调用缩放函数 local ret = resize.im_resize(body, n, tonumber(m[2]), tonumber(m[3]), '.jpg', ret_len); --返回结果 ngx.header['Last-Modified'] = res.header['Last-Modified']; ngx.print(ffi.string(ret, ret_len[0])); } }如此实现的图片缩放功能经测试,处理能力在300~400rps(CPU为AMD Ryzen 2200G启用OpenCL加速),基本上还可以接受。
MySQL Group Replication集群
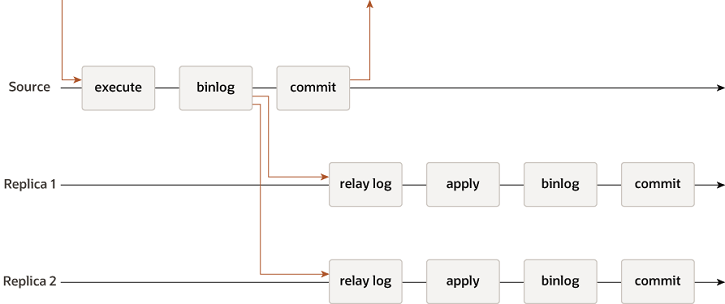
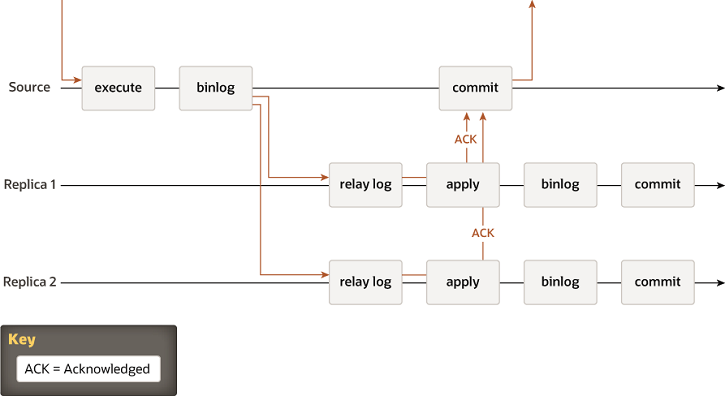
传统的MySQL的主从复制是主库通过binlog的形式将数据更新发送给从库,其中包含异步的复制,即主库完全不关心从库复制的情况就更新自身的数据,另外半同步复制则是主库需要等待至少一个从库将发送的binlog写入到其relaylog中才会更新自身的数据。
在此种复制模式下当主库发生故障时,从库的数据可能会存在不一致的问题,此时确定数据完全正确的从库(如果使用异步复制则可能会导致数据直接丢失,而不存在数据正确的从库)再重新调整各个从库之间的复制关系是个相对复杂的过程(尽管有一些工具能够自动处理这一过程)。
传统的异步复制
5.5中加入的半同步复制
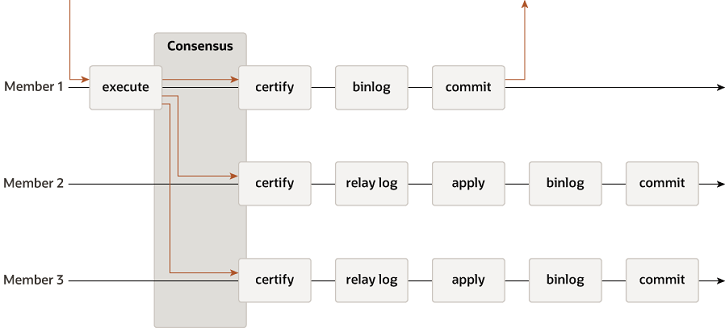
在MySQL 5.7中增加了Group Replication的复制方式,其实现了一种去中心化的复制方式,每个节点都具有相同的数据和地位(在Single-Primary模式下会决议确定一个写入的入口节点),当事务提交时,需要由多数节点决议来确定事务是否进行提交,以保证复制组内数据的一致性。当某个节点发生故障时Group Replication会自动剔除这个节点,如果故障的是Primary节点,则其他节点会决议来确定一个新的Primary节点。
5.7中加入的组复制
1. Group Replication的配置要求
使用Group Replication功能是需要保证满足以下条件
- MySQL版本需要在5.7.17以上
- 存储引擎全部使用InnoDB
- 全部表都必须有主键
- 网络为IPV4网络
使用Group Replication功能需要进行以下配置
#全部节点开启binlog log-bin=binlog #binlog格式必须为row格式 binlog-format=row #开启全局事务标识 gtid-mode=ON #复制信息存入系统表中 master-info-repository=TABLE relay-log-info-repository=TABLE transaction-write-set-extraction=XXHASH64 #开启复制日志 log-slave-updates=ON binlog-checksum=NONE
2. Group Replication的配置
配置组复制至少配置3个节点,需要进行的配置如下
#复制组的UUID标识 loose-group_replication_group_name="17da1ce4-040d-462e-a444-bfbf55a0f948" #启动后不自动加入复制组 loose-group_replication_start_on_boot=off #实例的组复制IP和端口 loose-group_replication_local_address= "127.0.0.1:24901" #复制组的成员IP和端口,不能使用主机名,用于新的成员加入复制组 loose-group_replication_group_seeds= "127.0.0.1:24901,127.0.0.1:24902,127.0.0.1:24903" #启动后初始化复制组,仅可在一个节点上设置为on loose-group_replication_bootstrap_group=off #单Primary节点模式 group_replication_single_primary_mode=on配置组复制使用的帐号,并开启组复制,需要注意每个节点的用户和密码需要相同
SET SQL_LOG_BIN=0; CREATE USER rpl_user@'%' IDENTIFIED BY 'password'; GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%'; FLUSH PRIVILEGES; SET SQL_LOG_BIN=1; CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='password' FOR CHANNEL 'group_replication_recovery';
3. 启动Group Replication
连接进入其中一个MySQL实例,执行以下操作开启组复制
INSTALL PLUGIN group_replication SONAME 'group_replication.so'; SET GLOBAL group_replication_bootstrap_group=ON; START GROUP_REPLICATION; SET GLOBAL group_replication_bootstrap_group=OFF;在另外的实例中执行开启组复制
START GROUP_REPLICATION;完成后查看状态可以看到
SELECT * FROM performance_schema.replication_group_members;+---------------------------+--------------------------------------+-------------+-------------+--------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | +---------------------------+--------------------------------------+-------------+-------------+--------------+ | group_replication_applier | 01b7de10-81e0-11e8-b5e0-080027f3c535 | archlinux | 24803 | ONLINE | | group_replication_applier | f5e1928b-81df-11e8-bda0-080027f3c535 | archlinux | 24801 | ONLINE | | group_replication_applier | fa8af292-81df-11e8-8566-080027f3c535 | archlinux | 24802 | ONLINE | +---------------------------+--------------------------------------+-------------+-------------+--------------+
4. 多Primary节点模式(Multi-Primary)
如果希望能够从任何一个节点都能进行读写操作,则需要将全部节点都增加配置
group_replication_single_primary_mode=off注意全部节点的这个配置必须全部都是相同的,否则配置不一致的节点启动组复制时会发生以下报错
Variables such as single_primary_mode or enforce_update_everywhere_checks must have the same value on every server in the group.另外在两个不同的节点同时进行锁定(SELECT FOR UPDATE),由于节点之间的锁时不能共享的,会造成两个节点上都能够锁定成功,但在事务提交时,后提交的事务会发生失败。
ERROR 1180 (HY000): Got error 149 during COMMIT为此还是建议直接使用Single-Primary模式。
5. 总结
Group Replication主要解决了传统主从复制方式在主库故障时可能数据丢失以及从库数据不一致并且切换复杂的问题,简化了MySQL集群的高可用设计,同时使用InnoDB Cluster结合MySQL Router便可以实现对于后端Primary节点和Secondary节点的自动选择,并且通过两个MySQL Router配置Keepalived后,就可以实现对后端MySQL Group Replication集群的透明访问。